waterfront,yr_renovated범주형으로 변환 및 인코딩보조변수yr_sold (date)와 연식h_age변수 추가연속형 변수min-max변환id, zipcode, date제외
저번 포스팅에서 연속형 변수의 전처리까지 수행했고, 이번에는 1.에 해당하는 범주형 전처리와 최종 파이프라인을 구현해보도록 합시다.
이전 포스팅 내용을 바로 확인하고 싶다면 클릭하세요!
» 전처리 파이프라인 만들기 1
» 전처리 파이프라인 만들기 2
범주형 변수를 위한 파이프라인
연식 h_age을 구할 때 사용되었던 yr_renovated를 이번에는 개조된 경우 1, 개조되지 않은 경우 0인 범주형 설명변수로서 변경하고자 합니다. 현재로서는 개조된 경우 1이 아닌 네 자리 개조 연도가 들어가있기 때문에 int형 변수로 인식됩니다. 이를 먼저 0과 1로 표현하기 위해 다음과 같은 LevelChanger 클래스를 생성합니다.
from sklearn.base import BaseEstimator, TransformerMixin
class LevelChanger(BaseEstimator, TransformerMixin):
def fit(self, C, y=None):
return self # nothing else to do
def transform(self, C, y=None):
for i in range(len(C)):
if C[i,1] != 0:
C[i,1] = 1
return C즉, 0이 아니라면 값을 1로 변경하는 노드를 추가했습니다. housing 데이터셋에서 범주형 설명변수는 binary형인 waterfront와 yr_renovated 뿐이기 때문에 추가적인 변환은 필요 없습니다. 이제 인코딩을 진행해야 하는데, 만약 회귀분석을 이용한다면 이제 진행할 인코딩은 건너뛰어도 됩니다.
회귀분석에서는 # of levels - 1로 범주형 설명변수 개수를 지정합니다. 그러나 머신러닝에서는 # of levels로 설명변수의 개수를 지정하는 경우가 있는데, 예를 들어 renovated 한 변수에서 yes와 no를 1과 0으로 구분하는 것이 아닌, renovated_yes, renovated_no 두 변수를 만들어서 각 변수가 yes 또는 no를 의미하도록 하는 것입니다. 이를 위한 인코딩은 사이킷런의 OneHotEncoder를 이용하면 됩니다.
이제 범주형 파이프라인 cat_pipeline을 다음과 같이 정의합니다. 연속형 파이프라인 ‘num_pipeline’과 비슷하게 사이킷런의 Pipeline을 이용하여 클래스들과 각각에 맞는 이름(selector, level, cat_encoder)을 적고 노드를 연결합니다. 이때 Pipeline은 연속된 변환을 순서대로 처리할 수 있도록 돕는 클래스입니다.
from sklearn.preprocessing import OneHotEncoder
cat_attribs = ["waterfront", "yr_renovated"]
cat_pipeline = Pipeline([
('selector', DataFrameSelector(cat_attribs)),
('level', LevelChanger()),
('cat_encoder', OneHotEncoder(categories='auto', sparse=False))
])위의 코드를 보면 연속형 파이프라인에서 사용했던 selector를 마찬가지로 이용하여 범주형 파이프라인에서 처리할 설명변수 cat_attribs를 인자로 넘겨 변환된 배열로 반환받습니다. 그리고 연결된 두 노드를 통해 인코딩까지 수행합니다.
최종 파이프라인
이쯤에서 파이프라인의 전체적인 구조를 한번 확인해보겠습니다. 지금까지 글로 설명해서 복잡해보일 수 있지만 다음과 같이 도식화하면 매우 간단해보입니다. 또한 이렇게 재사용 가능한 파이프라인을 생성하여 전처리를 수행하는 것이 얼마나 효율적인지 알 수 있습니다.
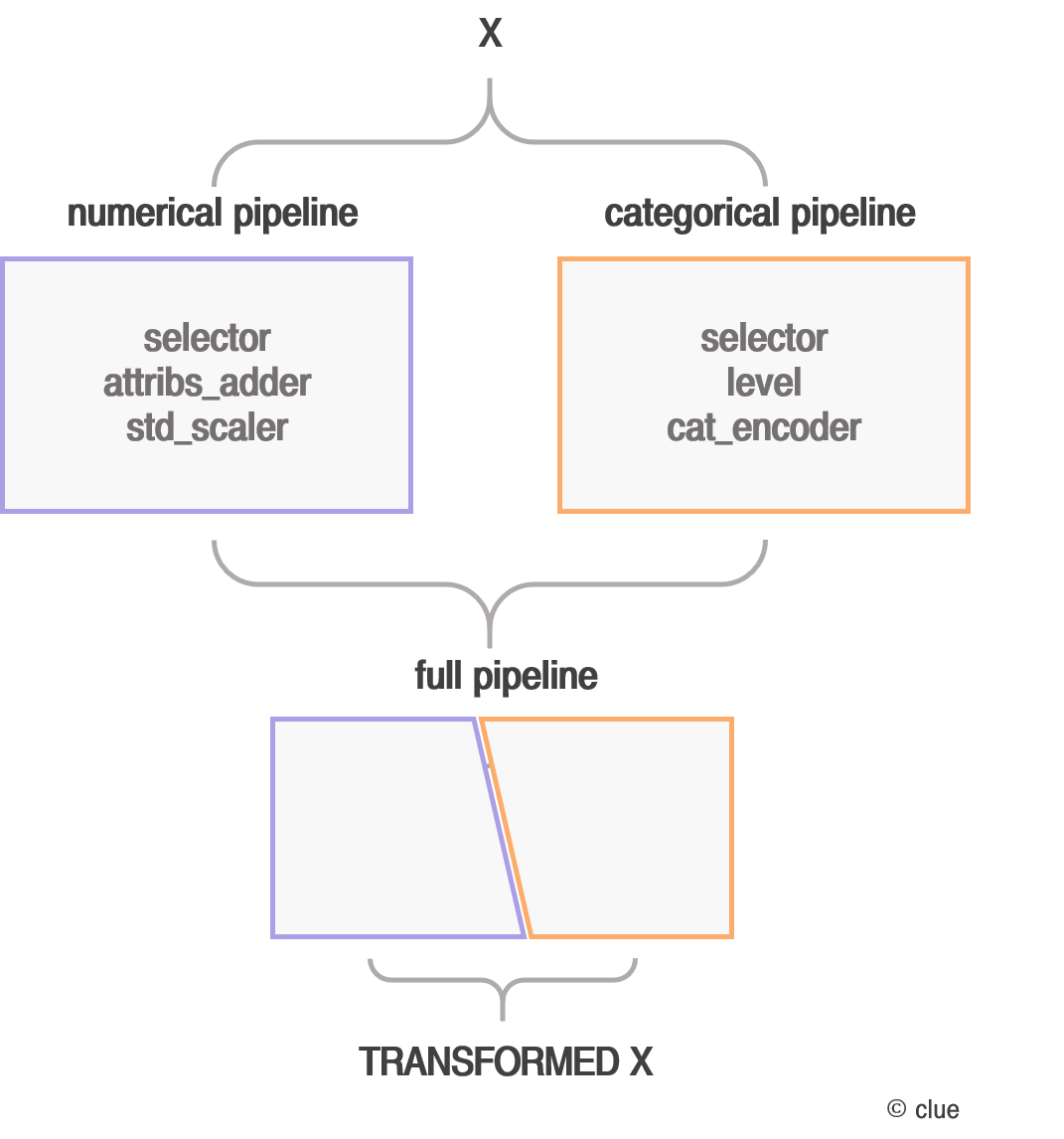
이제 두 파이프라인을 정의했으니 housing의 train set으로 확인을 해봐야겠죠? 포스팅에서는 순어에 맞춰 파이프라인을 모두 정의한 다음 최종 데이터셋 변환을 실행했으나, 각 파이프라인의 사실 클래스를 하나씩 추가할 때마다 제대로 수행되는지 계속 확인해봐야 합니다. 나중에 한번에 실행할 경우 에러를 찾고 코드를 변경하는데 오랜 시간이 걸리니 미리 확인은 필수입니다.
from sklearn.compose import ColumnTransformer
full_pipeline = ColumnTransformer([
("num_pipeline", num_pipeline, num_attribs),
("cat_pipeline", cat_pipeline, cat_attribs),
])먼저 num_pipeline과 cat_pipeline을 연결한 full_pipeline을 정의합니다. num_attribs와 cat_attribs는 앞에서 정의한 변수 이름이 들어갑니다. 다음으로 설명변수와 반응변수를 housing과 housing_labels로 나누고, 파이프라인은 train_set의 설명변수만 있는 housing만 넣고 수행합니다. 나중에 모델 생성하고 이를 테스트할 때는 물론 test_set으로 이 파이프라인을 돌린 후 모델에 넣고 진단을 하면 됩니다.
housing = train_set.drop("price", axis=1) # X
housing_labels = train_set["price"].copy() # Yhousing_full = full_pipeline.fit_transform(housing)
housing_full
housing_full은 배열로 반환됩니다. 원하는 대로 결과가 반환되었다면 성공입니다. 마지막으로 data.frame으로 변환 후 이번 포스팅을 마치도록 하겠습니다.
housing_tr = pd.DataFrame(
housing_full,
columns=list(housing.drop(["id", "date", "waterfront", "yr_renovated", "zipcode"], axis=1)) + ["h_age"] + ["watf_no"] + ["watf_yes"] + ["reno_no"] + ["reno_yes"])
housing_tr.head()