이번 블로그 내용은 머신러닝 도서 『Hands-On Machine Learning with Scikit-Learn and TensorFlow』 2장에서 다루는 내용들을 토대로 전처리 파이프라인 생성 방법에 주목하여 그 활용을 주관적으로 기록했습니다. 책에서 이용한 데이터셋과 비슷하지만 다른 데이터셋으로 내용을 전개했으며 책을 제대로 소화하기 위한 목적을 갖고 있습니다.
이번 포스팅에서는 파이프라인을 생성하기 전에 반드시 거쳐야하는 부분으로 ① 데이터셋 확인, ② 훈련셋과 테스트셋 나누기, ③ 간단한 시각화를 포함한 데이터셋 탐색, ④ 파이프라인에 추가할 전처리 아이디어 도출을 진행합니다. 이는 모든 프로젝트의 시작 단계에 반드시 필요한 과정이며 분석자 사고의 흐름을 따라갑니다.
이어지는 다음 포스팅에서는 본격적인 파이프라인을 생성합니다. 연속형과 범주형 변수를 처리하는 파이프라인을 각각 만든 후 이 둘을 합쳐 최종 파이프라인을 생성합니다.
다음 포스팅 내용을 바로 확인하고 싶다면 클릭하세요!
» 전처리 파이프라인 만들기 2 (연속형 변수)
» (포스팅 예정) 전처리 파이프라인 만들기 3 (범주형 변수 및 최종 합치기)
데이터셋 확인
Kaggle data-link를 통해 다운받은 housing은 워싱턴에서 가장 인구가 많은 군인 King County의 주택 정보와 가격이 포함된 데이터셋으로 2014년 5월부터 2015년 5월까지 거래된 정보를 바탕으로 합니다. 데이터셋을 읽어봅시다.
import pandas as pd
housing = pd.read_csv('C:/Users/kc_house_data.csv')
housing.shapehousing.head()총 21613 obs과 21 variables로 크진 않지만 학습을 위해 적당한 크기로 적절합니다. head()를 통해 데이터셋을 확인해봅시다. 집 크기 단위로는 주로 square feet을 사용하며 컬럼명들은 꽤나 직관적입니다. 독립 변수 Y는 price로 집값을 의미하며 이를 모델링하기 전에 반드시 거쳐야하는 전처리 단계를 진행해봅시다.
housing.info()NA가 없는 매우 깨끗한 데이터로 대부분 int나 float로 연속형 변수이며 변수 date는 obect형입니다. describe()를 통해 확인해보면 waterfront는 현재 int이지만 값의 범위가 0과 1뿐이므로 범주형 binary로 보는 것이 적당할 것 같습니다.
훈련 & 테스트셋 나누기
컬럼들에 대해 더 살펴보기 전에 Training Set과 Test Set를 분리합니다. 데이터 탐색 이전에 일부를 떼어놓는 이유는 테스트셋의 패턴을 미리 습득하여 낙관적인 추정을 하지 않기 위해서라고 이 책에서 설명하고 있습니다.
데이터셋이 크진 않기 때문에 테스트셋으로 20%를 떼어두도록 하겠습니다. 이때 데이터를 더욱 탐색하고 계층적 추출 방법 등을 사용할 수도 있지만 우리의 목적은 전처리 파이프라인 생성이니 이 부분은 깊게 다루지 않고 가장 간단한 랜덤 추출로 진행했습니다.
import numpy as np
from zlib import crc32
def test_set_check(identifier, test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio * 2**32
def split_train_test_by_id(data, test_ratio, id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio))
return data.loc[~in_test_set], data.loc[in_test_set] 랜덤 추출을 구현하는 방법은 많지만 나중에 데이터셋이 업데이트되어도 이전에 훈련셋이었던 데이터는 여전히 훈련셋이도록 분리하기 위해 고유한 값을 가지는 키 id로 해시값을 계산하고 해시의 마지막 바이트 값이 51(256의 20% 정도)보다 작거나 같은 샘플만 테스트셋으로 지정하는 방법을 사용했습니다. 책을 인용하여 다시 포인트를 짚어보면 다음과 같습니다.
- 여러번 반복 실행해도 동일한 테스트셋 유지
- 데이터셋이 업데이트되어 새로운 데이터가 추가되더라도 여전히 20%의 테스트를 갖지만 이전에 훈련 세트에 있던 샘플은 포함하지 않을 것
- 사실 이 내용은 이번 포스팅의 중요한 부분은 아니니 이해하지 않고 건너뛰셔도 됩니다.
앞에서 정의한 split_train_test_by_id() 함수를 이용하여 Training Set 80%와 Test Set 20%를 할당합니다. 그리고 헷갈리지 않도록 Train Set을 복사하여 housing 변수에 넣습니다.
train_set, test_set = split_train_test_by_id(housing, 0.2, "id")
housing = train_set.copy()데이터셋 탐색 with 시각화
다음으로 간단한 시각화와 함께 데이터셋을 탐색해보겠습니다. 컬럼부터 다시 확인합니다.
housing.describe()yr_renovated는 Q3까지 모두 0인데 max만 2015로 특이해서 이를 확인해본 결과 집이 개조된 적이 없으면 0, 개조된 경우 그 연도를 기록한 변수였습니다. 이는 연속형 변수로서 그대로 모델링에 사용할 경우 패턴으로서 해석이 불가능하다고 판단하여 추후 개조 여부를 나타내는 0 또는 1 값을 갖는 범주형 binary로 변경하는 것이 좋다고 생각했습니다.
그러나 이렇게 yr_renovated를 0과 1로 변경할 때의 정보 손실은 필연적입니다. 따라서 개조 연도를 정보로서 잘 활용할 수 있도록 연식을 의미하는 h_age 변수를 추가하기로 판단했습니다.
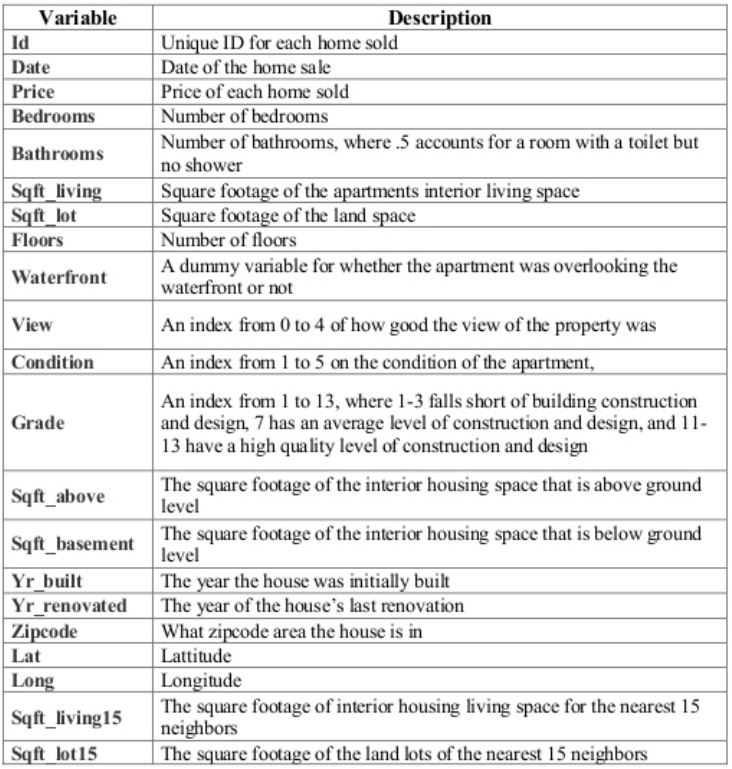
추가적인 변수 설명은 위의 표와 같습니다. view(0-4), condition(1-5), grade(1-13)는 ordinal한 값이기 때문에 범주형으로 변경하기보다는 연속형으로 그대로 이용하는 것이 좋겠다고 생각하여 그대로 진행했습니다.
변수들로 histogram을 그려본 결과 다음과 같습니다.
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()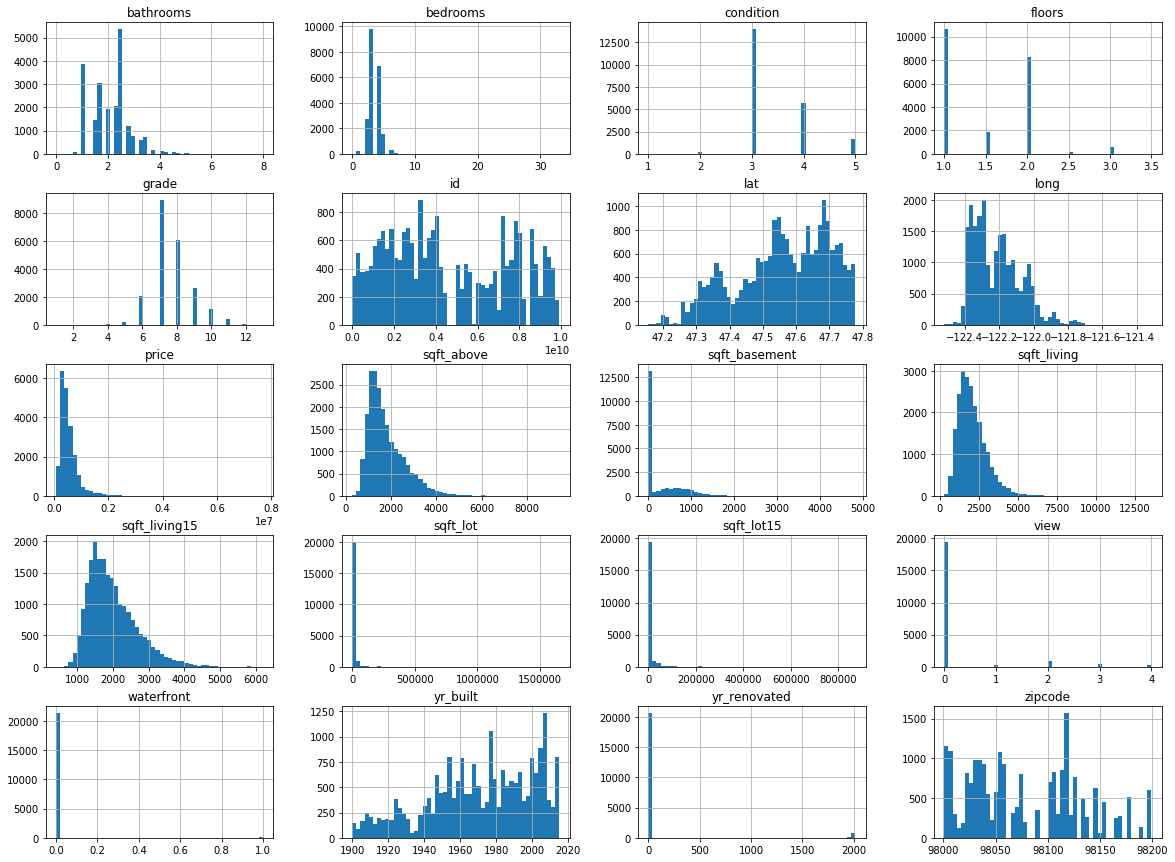
전반적으로 범위가 매우 달라 모든 변수에 min-max 변환을 적용하고자 합니다. 물론 경우에 따라 log 변환이나 변환을 사용하지 않을 수도 있지만 이번 포스팅의 V목적V에 걸맞게 변환 또한 파이프라인에서 처리해보도록 하겠습니다.
다음으로 위도와 경도를 나타내는 lat과 long으로 시각화한 결과입니다. 시각화를 보면 lat 보다는 long에 따른 주택 밀집 차이가 확연히 다르다는 점을 주목해볼 수 있습니다.
housing.plot(kind="scatter", x="long", y="lat", s=5, alpha=0.1) # 크기 size = 5, 투명도 alpha = 0.1
이제 예측하고자 하는 price에 영향을 주는 변수를 파악하기 위해 correlation을 확인해보겠습니다. price와 높은 상관관계가 있는 변수 중 일부를 선택하여 scatter plot도 그려봅시다.
from pandas.plotting import scatter_matrix
attributes = ["price", "sqft_living", "grade", "bathrooms", "view", "lat"]
scatter_matrix(housing[attributes], figsize=(12,8))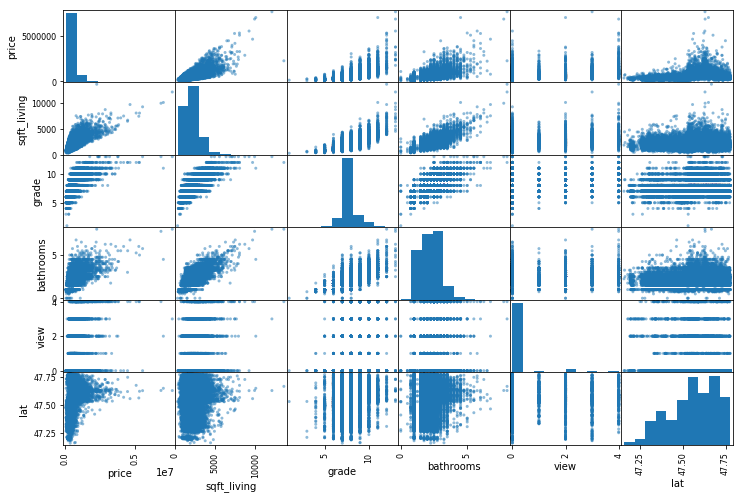
파이프라인에 추가할 전처리 아이디어
이전 단계로부터 다음과 같은 전처리 아이디어들을 얻을 수 있었습니다.
waterfront,yr_renovated범주형으로 변환- 연식
h_age변수 추가- 연속형 변수
min-max변환
더 구체화해보자면 1.은 범주형 변환 후 모델에 이용하기 위해 변수 인코딩이 필요합니다. 이 또한 파이프라인에 추가해야 합니다.
2.는 연식 변수를 추가하기 위해 보조 변수로서 건축 연도 yr_built와 집 거래 일자 date가 필요합니다. date는 20141013T000000과 같이 나타나기 때문에 연도가 되는 맨 앞 네 자리만 필요하며 전처리에 이 과정도 포함되어야 합니다. 더 자세한 내용은 다음 포스팅에서 다루도록 합시다.
3.의 min-max 변환은 연속형 변수를 대상으로 진행되어야 하며, 마지막으로 모델링에 활용하지 않을 변수 id, 우편번호 zipcode, 보조변수 date는 제외하는 것이 좋겠습니다.
이렇게 정리된 전처리 아이디어를 가지고 이만 다음 포스팅으로 넘어가겠습니다 :)
waterfront,yr_renovated범주형으로 변환 및 인코딩- 보조변수
yr_sold (date)와 연식h_age변수 추가- 연속형 변수
min-max변환id, zipcode, date제외