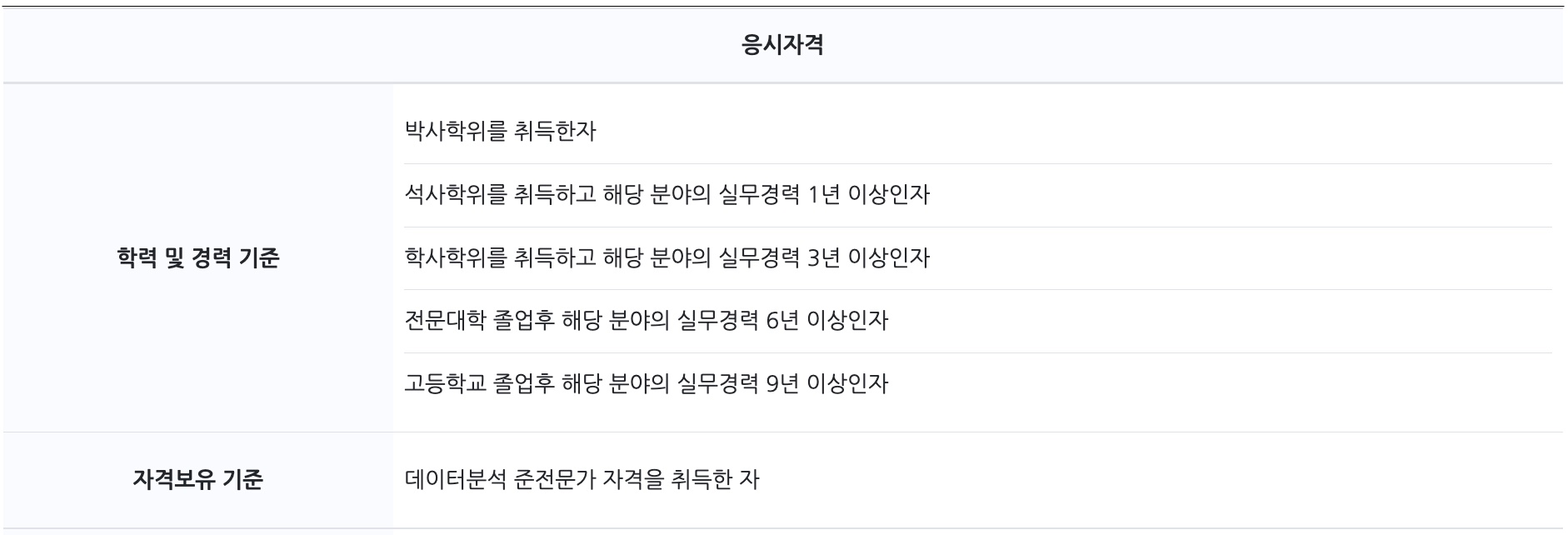
안녕하세요, 오랜만에 자격증 시험 후기를 들고왔습니다. 지난 8월 말에 제 26회 ADP 자격증의 필기 시험에 응시했고, 과락일 줄 알았는데 합격했습니다. 먼저 ADP는 자격 요건과 합격 기준이 다른 자격증들에 비해 조금 까다로운 편이니까 꼭 한 번 확인하고 필기를 접수하세요.
필기 시험일 이전에 아래의 자격 요건에서 경력/학력기준 또는 자격보유기준 중 한가지의 요건이 충족될 경우 응시자격이 부여됩니다. 주로 ADsP 자격증을 취득하고 ADP에 응시하는 경우가 많은 것 같습니다.
다음으로 필기 시험 합격 기준은 다음과 같습니다. 1. 총점 100점 기준 70점 이상, 그리고 2. 과목별 40% 미만 취득 으로 10문항씩 있는 1, 2, 3, 5단원의 경우 4문제 이상 맞춰야 합니다. 과락을 안 받는게 이 필기 시험의 포인트로 생각되네요.
문제를 생각나는 대로 복기해보았는데, 그냥 기억나는 내용들을 적은 것이니 참고용으로 보시길 바랍니다. 기억나는 대로 최대한 많이 적었는데, 문제가 될 시 삭제하도록 하겠습니다.
1단원
- 1)
- 데이터는 암묵지, 형식지의 상호작용에 있어 중요한 역할을 한다.
- 데이터는 그 자체로 의미가 없으며 객관적인 사실이다.
- 데이터는 창의적인 산물이다.
- 2)
- OLAP
- 3) 틀린 예시? (각 예시 존재)
- 사생활 침해: 개인정보 사용자의 책임
- 책임 원칙 훼손1
- 책임 원칙 훼손2
- 데이터 오용
- 4) 틀린 설명?
- 하드 스킬 2개
- 소프트 스킬 2개
- 5) 틀린 예시와 설명?
- 로직 오류
- 준비가 되지 않아서 분석에 차질이 생기는 경우 로직 오류인가
- 프로세스 오류
- 6) 위기 요인 틀린 설명?
- 사생활 침해
- 책임 원칙 훼손: 특정 성향의 사람을 채용에서 불이익
- 데이터 오용
- 7 )데이터 사이언티스트 요구 역량 가장 적절?
- 하드스킬
- 소프트스킬: 다분야간 협력을 위한 소통 능력
2단원
- 1) ETL 틀린 설명?
- 데이터 통합(integration)
- 데이터 이동(migration)
- 마스터 데이터 관리(Master data management)
- 데이터 정제?
- 2) ETL
- 추출
- 변형
- 적재
- 3) ETL 작업 단계
- interface -> stagging -> profiling -> cleansing -> integration -> denormalizing
- 4) 하둡, 맵리듀스
- 5) GFS 맞는 설명?
- 틀린 보기: 낮은 응답 지연시간이 높은 처리율 보다 더 중요하다.
- 맞는 보기: 파일에 대한 쓰기 연산은 주로 순차적으로 이뤄지며, 파일에 대한 갱신은 드물에 이뤄진다.
- 6) 틀린 설명?
- DW는 최신 데이터만 축적한다.
- 7) 운영체제 위에 가상의 운영체제를 구성하기 위한 운영 환경 계층을 추가하여 운영체제만을 가상화한 방식은?
- 메모리 기반 가상화
- 호스트 운영체제 기반 가상화 (*틀림)
- 컨테이너 기반 가상화 (*답)
- 하이퍼바이저 기반 가상화
- 8) EAI 활용 효과 적절한 것 모두 고르시오 (모두 맞음)
- 정보 시스템 개발 및 유지 보수비용 절감
- 기업 정보 시스템의 지속적 발전 기반 확보
- 협력사/파트너/고객과의 상호협력 프로세스 연계
- 웹 서비스 등 인터넷 비즈니스를 위한 기본 토대
- 9) 공유 디스크 장점 적절한 것?
- 클러스터를 구성하는 노드 중 하나의 노드만 살아있어도 서비스 가능 (*답)
- 클러스터가 커지면 디스크 영역 병목현상 발생 (틀림)
- 노드간의 동기화 작업 수행을 위한 별도의 커뮤니티 필요 없음 (틀림)
- 10) 분산시스템 설명 중 적절한 것 모두 고르시오 (모두 맞음)
- 빅테이블은 multi-dimension sorted hash map을 파티션하여 분산 저장하는 저장소
- SimpleDB의 데이터 모델은 Domain, Item, Attribute, Value로 구성되며 스키마가 없는 구조
- SSDS의 데이터 모델은 컨테이너, 엔티티로 구성
3단원
- 1) 하향식 접근 분석
- insight & discovery
- solution & discovery
- optimization & solution
- 2) 데이터 소스 파악이 어렵고 데이터 정확한 규정도 어려울 때 일단 분석 시도해보고 결과를 확인하며 반복적으로 개선해나가는 방법
- 하향식
- 폭포수
- 프로토타입 모델
- 3) 하향식 접근법
- 4) 거시적 관점에서 메가트렌드
- 기술
- 고객
- 경쟁자
- 파트너와 네트워크
- 5) 하향식 접근법에서 고객 관점에서 관심 사항이 아닌 것
- 경험
- 감정
- 기능
- 재무적
- 6) 분석 기획 시 우선순위
- 전략적 필요성 & 시급성
- 7) 세부 이행 계획 수립
- 고전적인 폭포수보다 반복적인 정련 과정을 통해 완성도 높이기
- 8) 맞는 것?
- 에이전시
- 디지털화
- 효율성
- 9) 분석을 위한 조직 구조
- 집중 구조: 전사 분석 업무를 별도의 분석 전담 조직에서 담당
- 기능 구조
- 분산 구조
4단원
- 1) 이산형 분포 아닌 것은?
- 기하
- 지수
- 포아송
- 이항
- 2) 시계열 정상성 설명
- 시간에 따라 분산이 변한다
- 시간에 따라 모수가 일정하다
- 3) 회귀 통계적 유의한지 확인하는 통계량
- F
- t
- 결정계수
- 4) 회귀에서 정규성 확인하는 방법 틀린 것은?
- 왜도첨도
- 결정계수
- qqplot
- ks test
- 5) 평균 계산: f(x)=1, 0<x<1 => 0.5
- 6) 척도 문제: 스피어만?
- 서열척도
- 7) 척도 문제: 온도, 지수, 절대적 0 없음
- 구간척도
- 8) 실제 true 중에 예측이 맞은 거?
- 오분류율
- 정확도
- 특이도
- 재현율(민감도)
- 9) 연관분석 신뢰도 구하기
- 40%
- 10) 연관분석 향상도 구하기
- 33% (*틀림)
- 11~15) 회귀 해석 문제: 로지스틱 회귀 해석/교호작용 있는지
- 16) 답 틀린 것?
- 정규성
- 선형성: 일정하게 상승한다
- 등분산성: 모든 변수에 대해 오차들이 일정하다 (*)
- 17) 범주형 변수 분석 시 틀린 방법?
- Log linear를 사용
- 주로 이항 분포와 포아송 분포를 활용
- 18) 다음 설명에 적절한 척도 (온도/지수, 절대적 0 없는 척도)
- 구간 척도
- 19) 표본 추출 방식 (샘플 나열 K씩 N구간으로 나누고 임의로 K개씩 띄어서 n개 표본 선택)
- 계통추출법
- 20) 클러스터링
- 초기 중심점에 영향을 받지 않는다
- 21) 다음 설명에 맞는 방법 (오분류한 데이터에 가중치 업데이트)
- 부스팅
5단원
- 1) 시각화 순서 나열
- 구조화 > 시각화 > 시각표현
- 2) 적절한 설명?
- 히트맵은 색으로만 구분한다
- 체르노프 페이스는 각 부위를 변수로 대체하여 속성을 쉽게 파악한다
- 스타차트는 하나의 변수마다 축 위의 중앙으로부터 거리를 수치로 나타낸다.
- 3) 다음 설명에 맞는 시각화 (몇 개의 축을 그리고, 하나의 변수마다 축 위의 중앙으로부터 수치 나타냄)
- 방사형
- 4) 연결 잘못된 것
- 시간 - 점그래프
- 분포 - ?
- 관계 - ?
- ? - 평행좌표계
- 5) 다음 설명에 맞는 시각화 (영역 기반의 시각화, 각 사각형의 크기가 수치)
- 트리맵
- 6) 벤 프라이 7단계 방법론 순서
- 획득 / 분해 / 선별 / 마이닝 / 표현 / 정제 / 상호작용
[서술형] (20점, 각 5점)
-
- train, test 과적합 문제
-
- 인공신경망 과적합 해결방법
-
- 두 모델의 정확도, f1score 계산
-
- 비교 후 어떤 모델이 더 좋은지
- => (b)의 f1 스코어가 더 높기 때문에 (b) 모델을 선택
- 비교 후 어떤 모델이 더 좋은지
생각나는대로 나왔던 개념과 선지 예시를 적어뒀고, 답은 따로 체크하지 않았습니다! 이런 내용들을 공부하시면 정말 무난히 합격하실 수 있습니다.
추가로 서술형에서 과적합 해결 방법으로 1. Dropout층 추가, L1, L2 규제 등 2. Early Stopping 수행이라고 적었습니다. 그 외에 Cross Validation, 하이퍼파라미터 튜닝 내용들도 무난하게 정답인 것 같습니다. 그리고 정확도와 f1-score 계산에서 공식 모두 자세히 적었습니다!
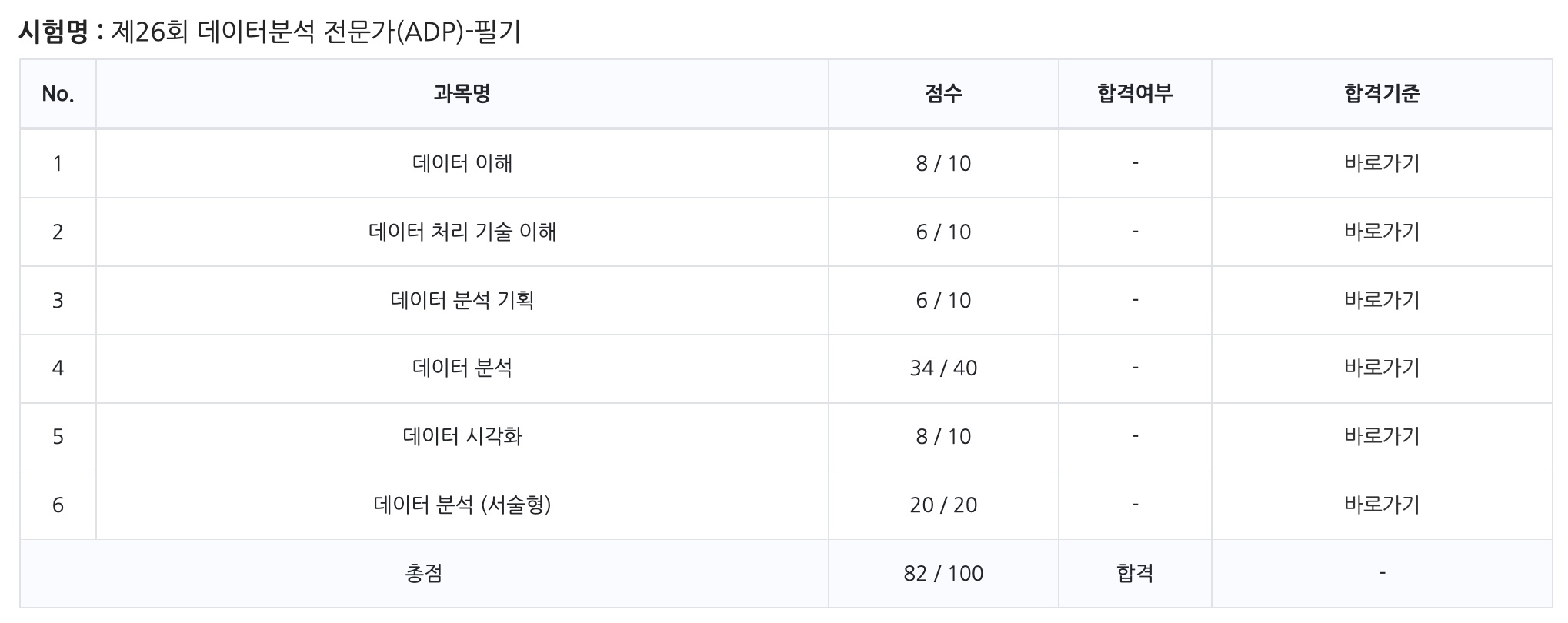
이제 기쁜 마음으로 실기를 신청하러 가야겠네요.