이번 포스팅에서는 pyspark dataframe의 pivot과 melt(unpivot)을 정리해보았다.
Pyspark Dataframe
먼저 pyspark dataframe을 하나 준비했다. pandas에서 간단하게 생성하고 pyspark으로 변경했고 다음과 같은 형태이다. 일주일 동안 세 사람의 걸은 횟수를 기록한 테이블 예시이다.
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from pyspark.sql.functions import *
from pyspark.sql import DataFrame
from typing import Iterable
sc = SparkContext.getOrCreate()
spark = SparkSession(sc)
import pandas as pd
pdf = pd.DataFrame({'country': ['Korea', 'UK', 'USA'],
'gender': ['m', 'f', 'f'],
'age': [32, 14, 24],
'2022-01-01': [12000, 7009, 2341],
'2022-01-02': [5040, 4310, 4315],
'2022-01-03': [9034, 5164, 3069],
'2022-01-04': [14031, 3513, 3543],
'2022-01-05': [11045, 8059, 4513],
'2022-01-06': [9834, 8104, 3952],
'2022-01-07': [13140, 6904, 1054]
})
df = spark.createDataFrame(pdf)
df.show()

Melt
현재 데이터는 short format 형태이다. 이 테이블은 집계 형식으로 나타날 때 장점이 있지만 SQL 형태로 조회하기가 어렵다. 또한 시각화용으로도 적절하지 않다. 이러한 테이블을 melt 함수를 이용해서 long format 형태로 변경해보려고 한다.
df.groupBy(['country']).agg(avg('age')).show()
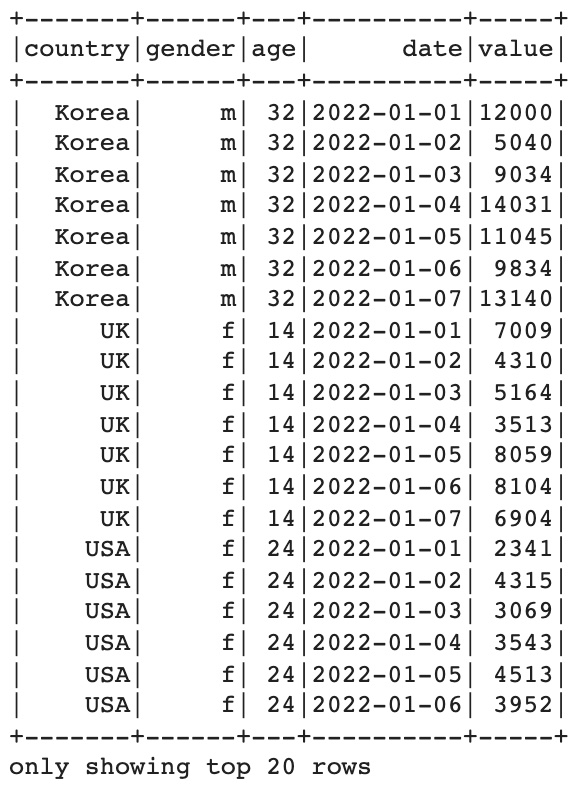
이 melt 함수는 stackoverflow에서 검색으로 알게된 함수로, 일반적인 unpivot 함수와 같은 기능을 한다. 그러나 Pyspark에서는 unpivot 함수가 따로 없기 때문에 melt 함수에 쓰인 explode 함수 등을 활용해야 한다. explode 함수는 다음과 같은 형태로 변경해준다.
# explode(): column 리스트를 하나의 각 row로 만드는 함수
# ex)
# id | alpha ==> id | alpha_explode
# 01 | [A, B] 01 | A
# 01 | B
위의 melt 함수보다 간단하게 변경하는 방법도 있다.
unpivotExpr = "stack(7, '2022-01-01', 2022-01-01, '2022-01-02', 2022-01-02, '2022-01-03', 2022-01-03, '2022-01-04', 2022-01-04, '2022-01-05', 2022-01-05, '2022-01-06', 2022-01-06, '2022-01-07', 2022-01-07) as (date, value)"
df.select("country", "gender", "age", expr(unpivotExpr)).show()
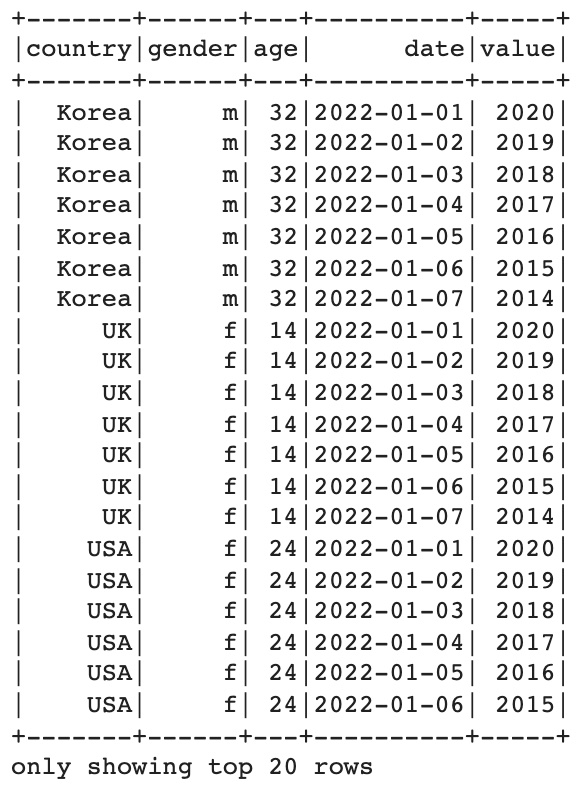
그러나 현재 데이터에서는 원하는 결과가 나오지 않는다. 생각대로라면 value 값에 2022-01-01 컬럼의 값 2341, 7009, 12000 등의 값이 들어가야하는데, 2022-01-01 = 2020, 2022-01-02 = 2019, … 즉 숫자로 변환되어 계산이 되어 들어간다. 이는 사실 컬럼 이름이 date로 되어있기 때문에 발생하는 특수 케이스이기 때문에 다른 데이터에서는 활용 가능할 것이다.
Pivot
다음으로 변경된 long format을 다시 short format으로 변경하는 방법이다. 이를 pivot 테이블이라고도 할 수 있으며 이는 하나의 컬럼의 값을 기준으로 여러 컬럼으로 만드는 것 파티션에 대해 정리하는 것을 의미한다. unpivot(melt)와 다르게 간단하게 변경할 수 있다.
short = long.groupBy("country", "gender", "age").pivot("date").sum("value")
short.show()
