이번 포스팅에서는 pyspark dataframe의 그룹, 파티션 내용을 정리해보았다.
Pyspark Dataframe
먼저 pyspark dataframe을 하나 준비했다. pandas에서 간단하게 생성하고 pyspark으로 변경했고 다음과 같은 형태이다.
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from pyspark.sql.functions import *
sc = SparkContext.getOrCreate()
spark = SparkSession(sc)
import pandas as pd
pdf = pd.DataFrame({'country': ['Korea', 'UK', 'Korea', 'USA', 'UK', 'Korea', 'UK', 'Korea', 'USA', 'UK'],
'gender': ['m', 'f', 'f', 'm', 'm', 'f', 'f', 'm', 'm', 'm'],
'name': ['Minsu', 'Jessie', 'Jisu', 'Arial', 'May', 'Sumi', 'Joel', 'Dukgu', 'Cloie', 'Violet'],
'age': [32, 14, 24, 23, 47, 12, 45, 29, 30, 16],})
df = spark.createDataFrame(pdf)
df.show()
groupBy
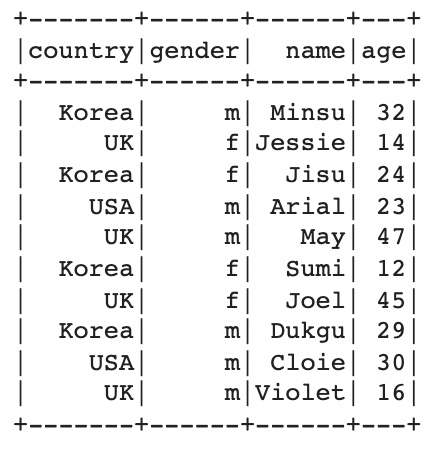
groupBy 함수를 사용하여 country 별로 평균 나이를 계산해보았다. 다음과 같이 agg 함수 내에 pyspark.sql.functions 내에 있는 avg 함수를 이용하여 평균값을 계산했다. max, min, count 또한 구할 수 있다.
df.groupBy(['country']).agg(avg('age')).show()
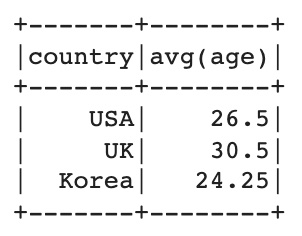
다음으로는 max, avg, count를 구했다. 컬럼의 이름은 보이는 것처럼 자동으로 변경된다.
df.groupBy(['country']).agg(max('age'), avg('age'), count('age')).show()
partitionBy
다음으로 파티션에 대해 정리한다. 쉽게 말해서 그룹의 경우 집약해서 데이터를 보여주는데, 이를 다시 펼치고 싶을 때 파티션을 사용한다. Windowing의 기능과 비슷하며, 다음의 예시를 살펴보자.
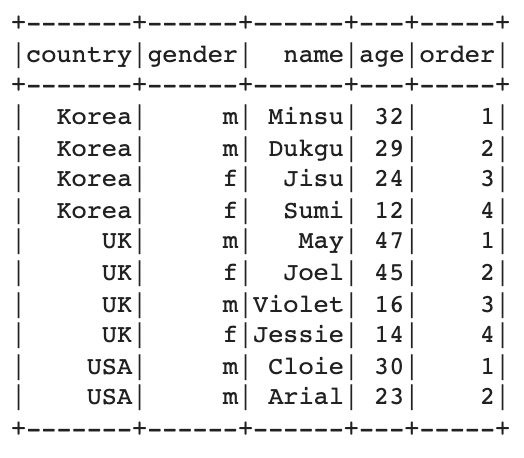
country 내에 age의 순위를 구하는 예시를 파티션을 이용하여 다음과 같은 코드로 얻을 수 있다. 이때, country를 기준으로 age의 내림차순을 윈도우에 이용하여 over(w) 코드를 통해 해당 윈도우 내에서 로우 인덱스, 즉 일종의 순위를 나타낼 수 있게 된다.
from pyspark.sql.window import Window
w = Window.partitionBy('country').orderBy(col('age').desc())
df.withColumn('order', row_number().over(w)).show()
다음은 country별로 속한 사람의 수를 n으로 나타내는 컬럼을 추가하는 코드이다. 파티션을 이용하여 집계와 다르게 각 행에 그룹 정보를 부착하는 형식으로 볼 수 있다.
from pyspark.sql.window import Window
w = Window.partitionBy('country')
df.withColumn('n', count(df['name']).over(w)).show()
다음으로는 country와 gender에 해당하는 사람들의 이름을 하나의 컬럼에 list 형태로 붙여넣은 예시이다. 여러 정보를 하나의 행에 부착할 때 유용하게 사용할 수 있다.
from pyspark.sql.window import Window
w = Window.partitionBy(['country', 'gender'])
df.withColumn('names', collect_list('name').over(w)).\
groupBy(['country', 'gender']).agg(count('age'), max('names')).show()

위의 dataframe에서 names를 list 형태가 아니라 string을 ‘,’로 구분한 형태로 바꾸기 위해서는 다음과 같이 작성하면 된다.
df.withColumn('names', collect_list('name').over(w)).\
groupBy(['country', 'gender']).agg(count('age'), max('names')).\
withColumn('names', concat_ws(", ", 'max(names)')).show()

위의 과정들을 종합하여 dataframe을 깔끔하게 나타내보았다. country, gender 별로 해당하는 사람 수를 구하고 그때의 이름을 names 컬럼에 나열한 결과이다. 기존의 max(names) 컬럼은 삭제했다.
df.withColumn('names', collect_list('name').over(w)).\
groupBy(['country', 'gender']).agg(count('age'), max('names')).\
withColumn('names', concat_ws(", ", 'max(names)')).drop('max(names)').withColumnRenamed('count(age)', 'n').show()
