저번 포스팅에 이어서 pyspark dataframe을 다루는 명령어들을 정리해보았다.
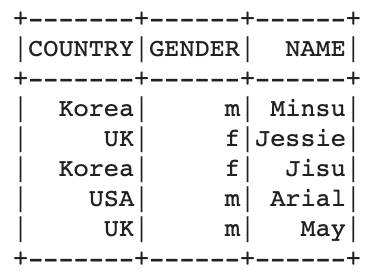
먼저 pyspark dataframe을 하나 준비했다. pandas에서 간단하게 생성하고 pyspark으로 변경했고 다음과 같은 형태이다.
from pyspark.context import SparkContext
from pyspark.sql.session import SparkSession
from pyspark.sql.functions import *
sc = SparkContext.getOrCreate()
spark = SparkSession(sc)
import pandas as pd
pdf = pd.DataFrame({'country': ['Korea', 'UK', 'Korea', 'USA', 'UK'],
'gender': ['m', 'f', 'f', 'm', 'm'],
'name': ['Minsu', 'Jessie', 'Jisu', 'Arial', 'May'],
'age': [32, 14, 24, 23, 47],})
df = spark.createDataFrame(pdf)
df.show()

count, PrintSchema
pyspark dataframe에서 count()는 행의 개수를 확인할 수 있다. 다음 명령어는 pandas dataframe의 shape와 동일한 역할을 한다.
print(df.count(), len(df.columns))
# 5 4
PrintSchema 함수를 통해서는 변수의 타입을 확인할 수 있다.
df.printSchema()
# root
# |-- country: string (nullable = true)
# |-- gender: string (nullable = true)
# |-- name: string (nullable = true)
# |-- age: long (nullable = true)
select
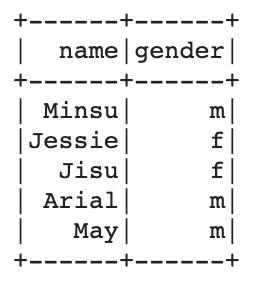
pyspark dataframe에서 특정 컬럼을 선택할 때는 select 함수를 이용한다. pandas dataframe과 다르게 슬라이싱 기능이 작동하지 않고.. 그게 매우 큰 불편함이긴 하나 spark는 분산으로 데이터를 관리하기 때문에 당연한 결과이다.
df.select('name', 'gender').show()
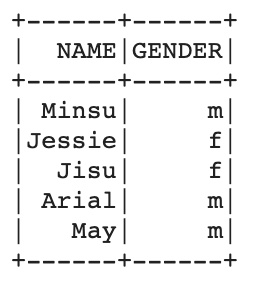
다음 코드는 select를 하되 컬럼명에 alias를 지정하여 선택하는 방법이다. 약간 pyspark dataframe을 사용하다보면 SQL 문이 구현 된 느낌을 많이 받는 것 같다.
df.select(col('name').alias('NAME'), col('gender').alias('GENDER')).show() # col은 pyspark.sql.functions 내에 있는 함수
filter
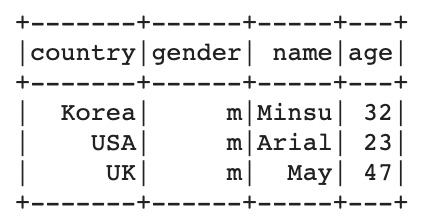
다음으로는 특정 row를 선택하는 방법이다. 슬라이싱 기능이 없는 pyspark dataframe에서 조건에 해당하는 행만 추출할 때 사용하므로 자주 사용하게 되는 함수이다.
df.filter(df.gender=='m').show()
orderBy
다음으로 데이터를 정렬하는 함수이다. pandas dataframe의 sort_values()와 비슷한 함수이다.
df.orderBy('age', ascending=False).show()

withColumnRenamed
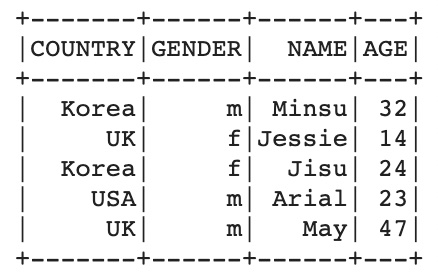
다음으로 변수명을 바꾸는 함수이다. for문을 이용하여 모든 컬럼명을 대문자로 변경해보았다.
for i in range(len(df.columns)):
df = df.withColumnRenamed(df.columns[i], df.columns[i].upper())
drop
다음으로 컬럼을 삭제하는 함수이다. AGE 컬럼을 삭제해보았다.
df.drop('AGE').show()