이번 블로그 내용은 머신러닝 도서 『Hands-On Machine Learning with Scikit-Learn and TensorFlow』 4장에서 다루는 경사 하강법(Gradient Descent) 내용을 정리하고자 하는 목적을 가지고 있습니다.
확률적 경사 하강법, 미니 배치 경사 하강법 내용을 보려면 다음 포스팅을 클릭하세요!
» 확률 경사 하강법 SGD, 미니 배치 경사 하강법 MGD
경사 하강법 / Gradient Descent
경사 하강법은 최적의 모델 파라미터를 찾기 위한 알고리즘으로 최적 추정치를 1. 수식으로 계산하기 어렵거나 2. 변수가 너무 많거나 3. training set이 너무 클 경우 많이 사용합니다. 이름에 걸맞게 현재 비용함수의 그래디언트가 0이 되는 방향으로 파라미터를 계속 업데이트하여 최적값을 찾는 방법입니다.
-
그래디언트는 비용함수의 미분한 값, y = ax + b + ε에서 그래디언트는a이고 x에 대한 미분으로 기울기 라고도 함, 파라미터가 여러 개일 때 각 파라미터에 대한 편미분하여 나온 벡터를그래디언트라고 함. -
비용함수는 파라미터를 찾는 일종의 기준으로 정의하기 나름이며, 이를 최소한으로 줄이는 파라미터를 찾는게 목적ex MSE
그래디언트를 0에 가깝게 만드는 이유는 무엇일까요? 먼저 쉬운 예제로 y = a(x-b)^2 + c에서 x에 대한 미분한 식이 0이 되는 지점을 구하면, 2a(x-b) = 0으로 x = b일 때 최솟값 c가 됩니다. 그래디언트가 0이 되는 방향으로 파라미터를 업데이트하는 것도 마찬가지로 비용함수를 최소로 줄이는 파라미터를 찾기 위함이며 예제처럼 x 하나가 아니라 파라미터가 여러 개인 일반적인 경우를 고려한 것입니다. 여러 파라미터에 대해 편미분하여 다차방정식을 푸는 것이 어렵기 때문에 대신 코딩을 통해 컴퓨터로 계산하여 추정치를 구하게 됩니다.
- 대학 미분적분학을 공부해본 적이 없다면 위 내용을 이해하기 어려울 수도 있습니다.
다시 정리하자면, 경사 하강법은 임의 초기값에서 시작하여 비용 함수가 감소하는 방향으로 파라미터를 업데이트하여 최솟값에 수렴하도록 하는 방법입니다. 모든 변수(특성)이 같은 스케일을 갖도록 만들어야 빠르게 수렴할 수 있어서 StandardScaler 등을 이용하여 표준화시키는 것을 추천합니다.
- 이때 최솟값은 지역 최솟값
(local minimum)이 아닌 전역 최솟값(global minimum)을 의미
다음 단락부터는 경사 하강법을 실제 코딩으로 구현하는 방법을 알아보고자 합니다. 특별히 필요한 패키지는 없습니다. 덧붙여 완벽한 최적값이 아니라 수렴하도록 근사하는 방법인 만큼 변이가 존재하여 구현 방법에 조금씩 차이가 있고, 크게는 배치 경사 하강법, 확률적 경사 하강법, 미니 배치 경사 하강법으로 나뉩니다. 이제 이 세 가지에 대해 자세히 알아보도록 합시다.
배치 경사 하강법 / BGD
배치 경사 하강법은 가장 기본에 충실한 방법입니다. 파라미터가 2개 이상인 경우를 주로 의미하며 위에서 설명한대로 매 스탭에서 training set 전체를 사용하여 그래디언트를 계산하고 파라미터를 업데이트합니다.
실제 예제를 통해 확인해봅시다! y = β0 + β1*x + ε 식으로 표현되는 linear regression의 파라미터 Β = [β0, β1]T의 추정치를 찾는 문제를 해결해봅시다. true B는 [6, -2]로 두도록 합시다. 100개의 랜덤 데이터를 만들어 ture y를 구하고, X_b로 bias를 고려한 항이 추가된 design matrix를 생성합니다.
-
T는 transpose로 전치를 의미
-
bias는 모든 원소가 1로 구성된 컬럼 벡터와 결합되는 β0를 의미
import numpy as np
X = 1.5 * np.random.rand(100, 1)
y = 6 - 2 * X + np.random.randn(100, 1)
# y = 6 - 2*x
X_b = np.c_[np.ones((100, 1)), X]이제 배치 경사법으로 Β 추정치인 Β_hat을 구해보도록 하겠습니다.
eta = 0.01 # 내려가는 스탭의 크기
n_iter = 10000 # 10000번 반복
m = 100 # sample 수
B_hat_BGD = np.random.randn(2,1) # B_hat 초기값
for iteration in range(n_iter):
gradients = 2/m * X_b.T.dot(X_b.dot(B_hat_BGD) - y)
B_hat_BGD = B_hat_BGD - eta * gradients
B_hat_BGDB_hat_BGD를 출력하면 [6.1480, -2.0521]T입니다. 처음에 X를 만들 때 랜덤한 파트가 존재했기 때문에 값이 같지 않을 수 있지만, true value인 [6, -2]T와 비슷한 값이 나왔고 성공적으로 최적점에 가까이 수렴했음을 알 수 있습니다.
잠깐 이론적인 내용을 짚고 넘어가봅시다. 위에서 gradients 식은 오차제곱합을 미분한 식입니다. 즉, 오차제곱합이 비용함수가 되고 y와 y의 예측치 사이의 차이를 최소화하는 방향으로 B_hat을 구하고자 하는 것입니다. 수식으로 구체적으로 나타내는 것은 생략하겠습니다. 그렇다면 이때, 가장 좋은 B_hat 추정치는 무엇일까요?
여기에는 여러 기준을 정할 수 있으나, 이론적으로 unbiasedness 또는 consistency 성질을 갖고 있다면 좋은 추정치라고 생각할 수 있습니다. 이때 많이 들어보셨을 B의 LSE(최소제곱추정치)는 ***BLUE(Best Linear Unbiased Estimator)**이고 이는 unbiasedness를 만족하는 y에 linear한 추정치 중 가장 분산이 작으며 현재 우리가 비용함수로 둔 것이 바로 최소제곱추정치를 구하기 위한 오차제곱합 입니다.
- BLUE 성질은 Gauss-Markov Theorem에 의해 증명
다음의 이론적인 정리가 이해되지 않더라도 경사 하강법을 이해하는데는 문제가 되지 않습니다.
[ 이론 정리 ]
MCE는 contrast function을 최소화하는 추정치를 의미하고 constrast function을 비용함수라고도 한다. contrast function을 무엇으로 설정하느냐에 따라 추정치의 명칭이 달라지는데, MLE, LSE가 가장 중요하다.
- MLE: contrast function으로 -Likilihood를 사용
- LSE: contrast function으로 오차제곱합을 사용
선형회귀에서 정규성 가정을 할 때 정규분포의 Maximum Likelihood가 오차제곱합의 식과 굉장히 비슷해진다.
(2차항 때문)따라서 B hat을 구할 때는 MLE = LSE이며, linear regression에서 오차의 정규분포 가정 시 정규분포의 표준편차 추정치인 sigma hat를 구할 때는 MLE ≠ LSE이다.
그렇다면 B의 LSE(최소제곱추정치)를 구해서 이를 배치 경사 하강법으로 구한 B_hat_BGD과 비교해볼까요? LSE는 다음과 같은 행렬 곱으로 구할 수 있습니다.
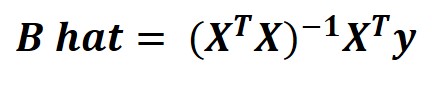
B_hat = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y) # linalg : 선형대수 모듈선형대수 모듈 linalg를 사용하여 역행렬을 구하고 위 식을 계산해서 구한 LSE인 B_hat의 결과는 [6.04, -1.99]로 true value인 [6, -2]와 굉장히 비슷합니다. 위에서 구한 배치 경사 하강법을 이용한 추정치 B_hat_BGD [6.1480, -2.0521]과도 비슷하나, LSE가 true value에 조금 더 가까운 것을 확인할 수 있습니다.
그렇다면 경사 하강법을 이용하여 최적값을 잘 찾기 위해서는 어떻게 해야 할까요? 앞에서 살펴본 바와 같이 학습률(η)과 초기값이 중요합니다. 다음과 같은 식으로 다음 스탭을 업데이트하기 때문에 학습률이 너무 크면 전역 최솟값을 벗어날 수도 있고, 학습률이 너무 작으면 지역 최솟값에 빠지거나 수렴에 너무 오랜 시간이 걸릴 수 있습니다.

학습률의 중요성을 짚어보기 위해 다음 두 코드 블럭을 실행해봅시다. 이는 학습률이 0, 0.01, 0.001일 때 각각 파라미터가 수렴해가는 과정을 확인한 것입니다.
B_path_BGD = []
def plot_gradient_descent(B_hat, eta, B_path=None):
m = 100
plt.plot(X, y, "b.")
n_iter = 10000
for iter in range(n_iter):
if iter%1000 == 0:
X_new = np.array([[0], [1.5]]) # X의 범위 [0, 1.5]
X_new_b = np.c_[np.ones((2, 1)), X_new]
y_predict = X_new_b.dot(B_hat)
style = "r-" if iter > 0 else "g--"
plt.plot(X_new, y_predict, style)
gradients = 2/m * X_b.T.dot(X_b.dot(B_hat) - y)
B_hat = B_hat - eta * gradients
if B_path is not None:
B_path.append(B_hat)
plt.xlabel("$x_1$", fontsize=18)
plt.axis([0, 1.5, 0, 10])
plt.title(r"$\eta = {}$".format(eta), fontsize=16)import matplotlib.pyplot as plt
np.random.seed(42)
B_hat_BGD = 2*np.random.randn(2,1) # random initialization
plt.figure(figsize=(10,4))
plt.subplot(131); plot_gradient_descent(B_hat_BGD, eta=0.0)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.subplot(132); plot_gradient_descent(B_hat_BGD, eta=0.01, B_path=B_path_BGD)
plt.subplot(133); plot_gradient_descent(B_hat_BGD, eta=0.001, B_path=B_path_BGD)
plt.show()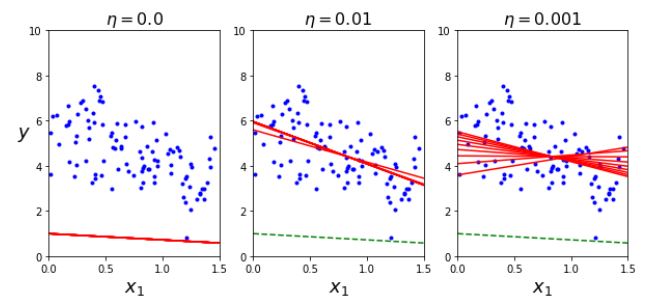
추가적으로 데이터로부터 결정되는 파라미터와 다르게 하이퍼 파라미터는 데이터로부터 결정되는 것이 아니라 모델링 시 분석자가 직접 설정하는 값을 의미하는데, 경사 하강법을 이용할 경우 학습률, 초기값과 같은 하이퍼 파라미터가 존재합니다. 이때, 다음과 같은 의문이 생길 수 있습니다.
하이퍼 파라미터 잘 조절해서 정규방정식으로 구한 것과 마찬가지로 최소 분산 예측치(LSE)를 구하는 것이라면 왜 굳이 경사하강법을 사용해야 하나? 이는 계산복잡도 때문입니다! 수학과 통계학에서는 여러 수학적 이론이 뒷받침 되는 것을 중시하지만 컴퓨터공학으로 넘어와 실제 구현을 위해서는 효율적인 알고리즘으로 빠른 계산을 해내는 것도 중요합니다. 이때 정규방정식으로 푼 LSE의 계산 복잡도는 O(n^3)으로 변수 개수가 늘어날 수록 시간이 세제곱배로 증가합니다.
지금까지 경사 하강법 알고리즘에 대한 이해와 배치 경사 하강법을 알아보았습니다. 확률 경사 하강법, 미니 배치 경사 하강법은 다음 포스팅에 이어나가겠습니다.
» 확률 경사 하강법 SGD, 미니 배치 경사 하강법 MGD