지리 정보를 시각화할 때 QGIS 등의 툴을 사용할 수도 있으나 rough한 시도별 또는 구별 수치 시각화는 R과 R Studio를 이용해서 어렵지 않게 그려볼 수 있습니다. 이러한 그래프는 시도별 또는 구별 특징을 한눈에 보기 쉽게 도식화할 때 매우 유용합니다.
- 주의: 내용을 따라하기 위해서는 R과 R Studio가 필요합니다.
서울특별시 구별 지도 시각화
먼저, 필요한 패키지들을 설치합니다. 이때 순서대로 설치하는 것이 중요합니다.
install.packages("ggmap")
install.packages("ggplot2")
install.packages("raster")
install.packages("rgeos")
install.packages("maptools")
install.packages("rgdal")-
ggplot2 패키지는 이미 있다면 건너뛰고 설치하시면 됩니다.
-
ggmap import 시 knitr 패키지가 없다고 해서 이 또한 설치해주었습니다.
패키지 설치가 완료되면 순서대로 import 합니다.
library(ggmap)
library(ggplot2)
library(raster)
library(rgeos)
library(maptools)
library(rgdal)다음으로 그림을 그리기 위해서는 두 데이터셋을 준비해야 합니다. 첫 번째는 시각화 대상이 되는 데이터셋입니다. 다음 테이블처럼 구별로 정리된 데이터셋이 필요한데, sample.csv를 이용해보셔도 좋습니다. 제가 임의로 만든 sample.csv의 시각화 대상은 A, B 컬럼의 랜덤 숫자 값입니다.
| 시도명 | 시군구명 | id | A | B |
|---|---|---|---|---|
| 서울 | 종로구 | 11110 | 2296 | 121 |
| 서울 | 중구 | 11140 | 2811 | 1469 |
| 서울 | 용산구 | 11170 | 1648 | 2254 |
| 서울 | 성동구 | 11200 | 3519 | 1801 |
sample.csv가 아닌 시각화할 본인의 데이터셋을 이용할 때는 데이터셋에 id 컬럼을 추가해야 합니다. 위의 sample.csv 표에서 확인할 수 있듯이 id 컬럼이란 각 구별 고유한 식별자입니다. 2020년 기준 서울시에 25개의 구가 존재하며 각 구는 고유한 id를 갖습니다. 각자 시각화할 본인의 데이터셋에 seoul_id.csv를 이용해 join 함수 등을 이용하여 id 컬럼을 추가하시기 바랍니다.
-
본인의 데이터셋에도 seoul_id.csv를 join하기 위해서는 key가 될 수 있는
시군구명컬럼이 필요합니다. -
이렇게 id 컬럼을 추가해야 하는 이유는 지도에 표시할 때
종로구,중구등이 아닌 id1111011140등을 기준으로 삼기 위해서입니다.
두 번째로 지리 정보 데이터셋이 필요합니다. click-site-link에서 시군구의 2017년 3월 업데이트 다운로드를 클릭하여 다운받습니다.
- 최신 자료의 경우 구별로 겹치는 포인트가 있어 코딩 중 오류가 뜨기 때문에 행정구역에 큰 변화가 없다고 가정하고 2017년 3월 자료를 이용했습니다.
다운로드 후 압축 파일을 풀면 SIG_201905 폴더 내에 확장자 .dbf, .prj, .shp, .shx인 네 파일을 확인할 수 있습니다. 이 중에서 shapefile인 TL_SCCO_SIG.shp를 이용할 것입니다. 해당 데이터셋에는 구별 좌표계 정보가 들어있습니다. 이제 두 자료를 R Studio로 불러옵니다.
P <- read.csv("C:/sample.csv", header = TRUE) #시각화할 데이터셋
map <- shapefile("C:/SIG_201703/TL_SCCO_SIG.shp") #지리 정보 데이터셋본격적인 시각화를 위해 몇 가지 단계를 가쳐야 합니다. 먼저, map을 spTransform() 함수를 이용하여 좌표계 변환을 진행해야 합니다.
map <- spTransform(map, CRSobj = CRS('+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs'))- 참고로 변환 전과 후의 형식 변화를 확인하고 싶다면 앞 뒤에
map@polygons[[1]]@Polygons[[1]]@coords %>% head(n = 10L)를 실행하여 1-10행 좌표를 확인해보시기 바랍니다. %>% 연산자 사용을 위해서는 dplyr 패키지가 필요하므로 import 후 확인하면 됩니다.
다음으로 fortify() 함수를 이용하여 map을 data frame으로 변환합니다. 이때, region = ‘SIG_CD’ 옵션으로 인해 SIG_CD 컬럼이 id로 변환됩니다.
new_map <- fortify(map, region = 'SIG_CD')
View(new_map)변환 후 View()를 통해 확인해보면 드디어 저희가 알아볼 수 있는 data frame 형태가 되었습니다. 위치를 나타내는 경도(long)와 위도(lat), 그리고 뒤에서 merge의 기준이 될 id를 확인해볼 수 있습니다.
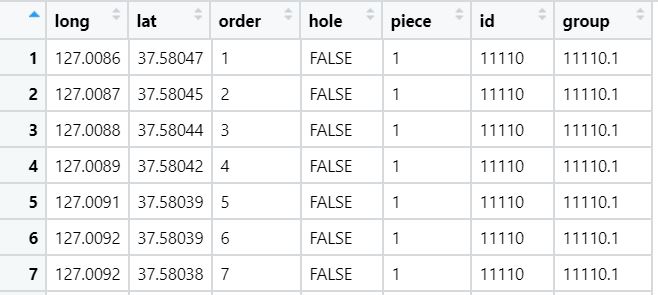
참고로 지리 정보 자료에는 대한민국 모든 구가 포함되어 있는데, id가 11740 이하가 서울시 구에 해당합니다. 따라서 현재 문자형인 id 변수를 숫자로 변환한 후 11740 이하만 추출하여 seoul_map 변수를 생성합니다.
new_map$id <- as.numeric(new_map$id)
seoul_map <- new_map[new_map$id <= 11740,]시각화할 자료와 seoul_map에 id 변수가 존재할테며 이를 key로 조인을 할 차례입니다. 다음과 같이 merge() 함수를 이용합니다.
P_merge <- merge(seoul_map, P, by='id')지금까지 에러 없이 잘 따라왔다면 서울시 구별 지도 시각화 준비가 완료된 것입니다. 짝짝!
먼저 구별 경계를 그려보도록 하겠습니다.
ggplot() + geom_polygon(data = P_merge, aes(x=long, y=lat, group=group), fill = 'white', color='black')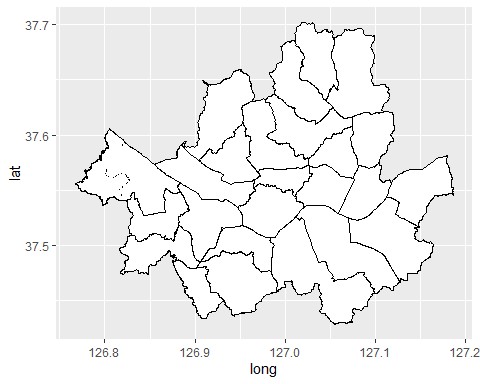
기본 틀 그림에 성공하셨나요? 이제 fill=A로 옵션을 변경하면 A를 연속형 변수로 인식하여 다음과 같이 구별로 값에 따라 진하기가 다른 지도가 그려집니다.
ggplot() + geom_polygon(data = P_merge, aes(x=long, y=lat, group=group, fill = A))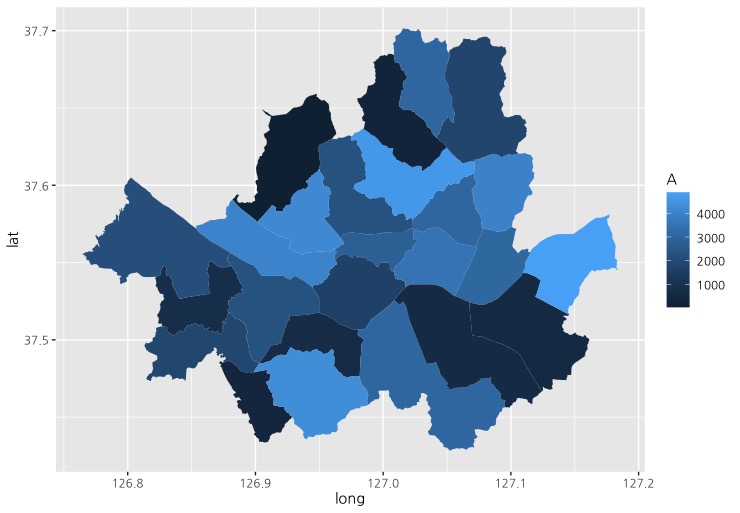
이제부터 ggplot을 활용하여 지도를 변형하시면 됩니다. 다음 코드도 참고해보세요.
# 맥 사용자라면 theme_set(theme_bw(base_family='NanumGothic')) 를 먼저 수행하고, 대신 + theme_bw() 코드를 제거하고 수행하세요.
plot <- ggplot() + geom_polygon(data = P_merge, aes(x=long, y=lat, group=group, fill = A))
plot + scale_fill_gradient(low = "#ffe5e5", high = "#ff3232", space = "Lab", guide = "colourbar")
+ theme_bw() + labs(title = "서울시 A 분포")
+ theme(panel.grid.major.x = element_blank(), panel.grid.minor.x = element_blank(), panel.grid.major.y = element_blank(), panel.grid.minor.y = element_blank(), plot.title = element_text(face = "bold", size = 18, hjust = 0.5))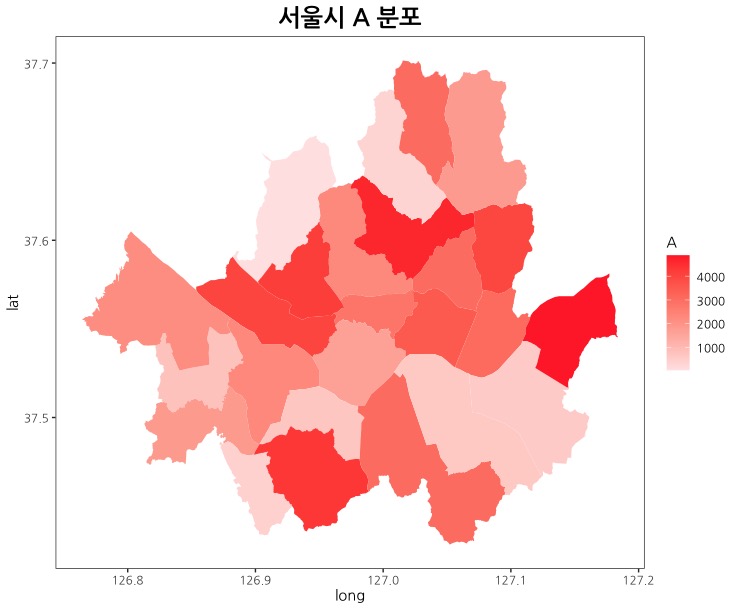
- ggplot 코드: plot에 기본 틀을 넣고 ggplot의 여러 함수로 세부 옵션 조정. scale_fill_gradient()를 통해 숫자가 높으면 진한 색, 숫자가 낮으면 연한 색으로 구분할 수 있도록 변경, theme_bw()로 뒷배경 제거, labs()로 제목 추가, theme()으로 plot의 기본 격자 제거
B에 대한 plot도 그려보시면 A와 B의 색이 진한 부분과 연한 부분이 달라 분포의 차이가 확연히 들어옵니다.
# 맥 사용자라면 theme_set(theme_bw(base_family='NanumGothic')) 를 먼저 수행하고, 대신 + theme_bw() 코드를 제거하고 수행하세요.
plot <- ggplot() + geom_polygon(data = P_merge, aes(x=long, y=lat, group=group, fill = B))
plot + scale_fill_gradient(low = "#ffffe5", high = "#ffb825", space = "Lab", guide = "colourbar")
+ theme_bw() + labs(title = "서울시 B 분포")
+ theme(panel.grid.major.x = element_blank(), panel.grid.minor.x = element_blank(), panel.grid.major.y = element_blank(), panel.grid.minor.y = element_blank(), plot.title = element_text(face = "bold", size = 18, hjust = 0.5))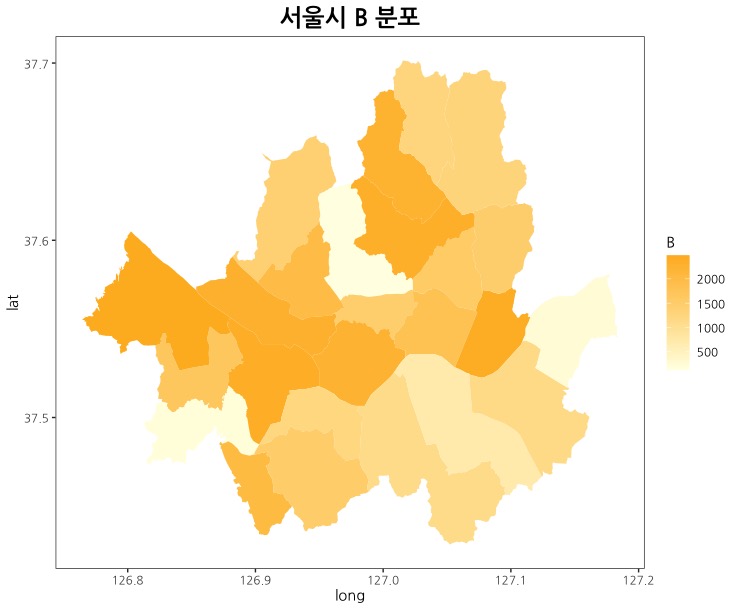
색을 조정하는 방법은 굉장히 많으니 다양한 방법을 시도해보시면 좋겠습니다 :)